|
|
|
PhD student at Princeton University I am interested in Artificial Intelligence, with a focus on Multitask and Multimodal Learning. I aim to leverage Natural Language Processing and Machine Learning to solve challenging problems in the Sciences. Previously was at Polytechnic University of Catalonia, Barcelona Tech (UPC) jointly working with Prof. Marta R. Costa-jussà and Carlos Escolano on LUNAR project to improve Neural Machine Translation for Extremely Low Resource Language. During my time at UPC, I was fortunate to do a research internship at Meta AI with the NLLB team (New York office) under the supervision of Angela Fan. I did my Master and Undergraduate in Computer Science in China at University of Electronic Science and Technology of China (UESTC). During my Master, I did internships at Huawei and WhaleCloud as an Artificial Intelligence (AI) Engineer. While at UESTC, I have received several awards including China Government Outstanding International Master Student Award, UESTC Outstanding Master Student Award, and UESTC Outstanding Undergraduate Student Award. CV / Google Scholar / LinkedIn / Github / Twitter / Email: rn3004 at princeton dot edu |

|
|
|
My research in natural language processing during my Master spans several topics. I have worked on machine translation, language modeling, text classification, summarization, sentiment analysis, common sense reasoning, named-entity recognition, and dataset creation and curation for low-resourced African languages. |

|
This paper describes the OCCGEN toolkit, which allows extracting multilingual parallel data balanced in gender within occupations. OCCGEN can extract datasets that reflect gender diversity (beyond binary) more fairly in society to be further used to explicitly mitigate occupational gender stereotypes. We propose two use cases that extract evaluation datasets for machine translation in four high-resource languages from different linguistic families and in a low-resource African language. Our analysis of these use cases shows that translation outputs in high-resource languages tend to worsen in feminine subsets (compared to masculine), specially in the directions containing English. This is confirmed by the human evaluation. We hypothesize that a sound language generation may contribute to pay less attention to the source sentence and to overgeneralize to the most frequent gender forms. |
|
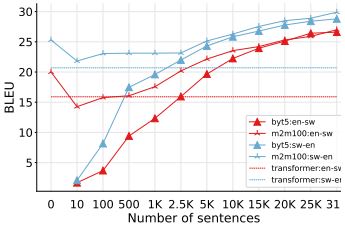
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data. |
|
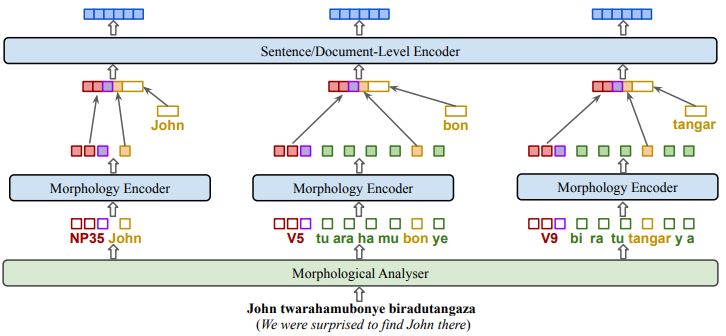
Pre-trained language models such as BERT have been successful at tackling many natural language processing tasks. However, the unsupervised sub-word tokenization methods commonly used in these models (e.g., byte-pair encoding - BPE) are sub-optimal at handling morphologically rich languages. Even given a morphological analyzer, naive sequencing of morphemes into a standard BERT architecture is inefficient at capturing morphological compositionality and expressing word-relative syntactic regularities. We address these challenges by proposing a simple two-tier BERT architecture that leverages a morphological analyzer and explicitly represents morphological compositionality. Despite the success of BERT, most of its evaluations have been conducted on high-resource languages, obscuring its applicability on low-resource languages. We evaluate our proposed method on the low-resource morphologically rich Kinyarwanda language, naming the proposed model architecture KinyaBERT. A robust set of experimental results reveal that KinyaBERT outperforms solid baselines by 2% F1 score on a named entity recognition task and by 4.3% average score of a machine-translated GLUE benchmark. KinyaBERT fine-tuning has better convergence and achieves more robust results on multiple tasks even in the presence of translation noise. |
|
GEM is a benchmark environment for Natural Language Generation with a focus on its Evaluation, both through human annotations and automated Metrics. It aims to measure NLG progress across many NLG tasks across languages, audit data and models and present results via data cards and model robustness reports, and develop standards for evaluation of generated text using both automated and human metrics. |
|
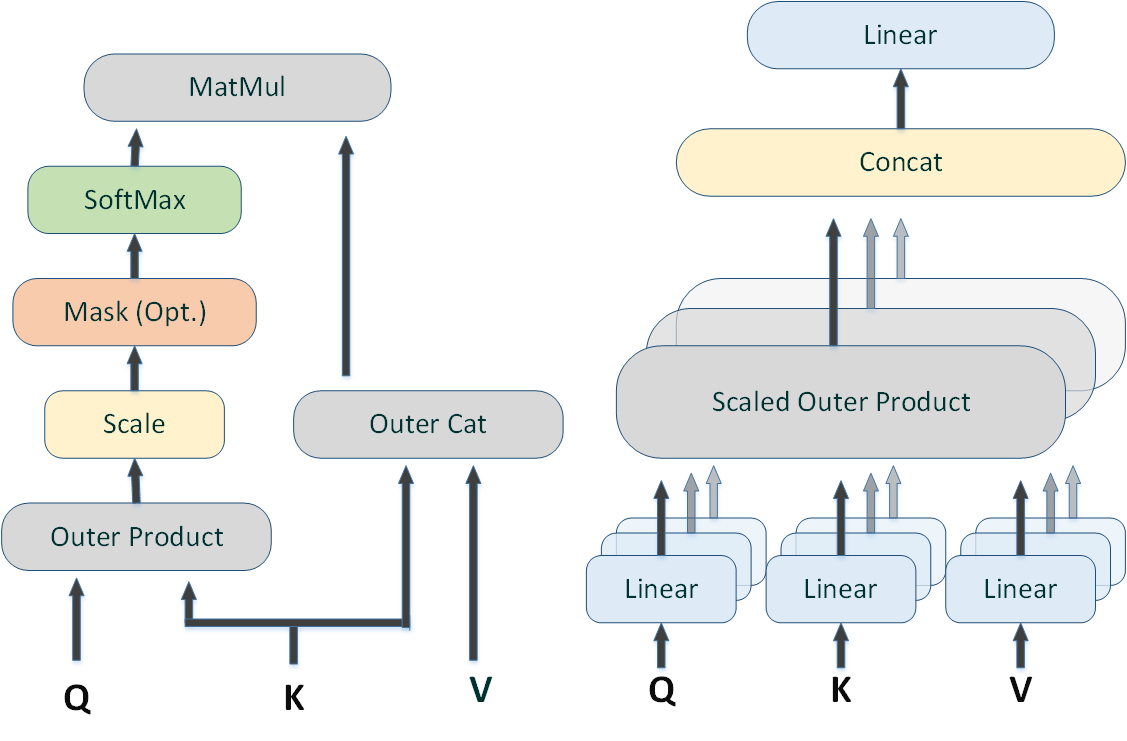
Machine Reading Comprehension is defined as the ability of machines to read and understand unstructured text and answer questions about it. It is considered as a challenging task with wide range of enterprise applications. Wide range of natural language understanding and reasoning tasks are found embedded within machine reading comprehension datasets. This requires effective models with robust relational reasoning capabilities to answer complex questions. Reasoning in natural language is a long-term machine-learning goal and is critically needed for building intelligent agents. However, most papers heavily depend on underlying language modeling and thus pay little to no attention on creating effective reasoning models. This paper proposes a modified transformer architecture that effectively combines soft and hard attention to create multi-perspective reasoning model capable of tackling wide range of reasoning tasks. An attention mechanism that highlights the relational significance of input signals is considered as well. The result from this study shows performance gain as compared to its counterpart the transformer network on bAbI dataset, a natural language reasoning tasks. |

|
We take a step towards addressing the under- representation of the African continent in NLP research by bringing together different stakeholders to create the first large, publicly available, high-quality dataset for named entity recognition (NER) in ten African languages. We detail the characteristics of these languages to help researchers and practitioners better understand the challenges they pose for NER tasks. We analyze our datasets and conduct an extensive empirical evaluation of state- of-the-art methods across both supervised and transfer learning settings. |
|
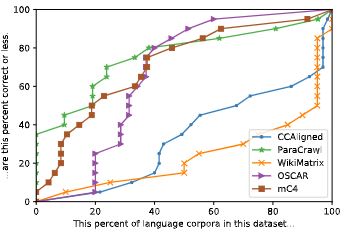
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, Web-mined text datasets covering hundreds of languages. We manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4). Lower-resource corpora have systematic issues: At least 15 corpora have no usable text, and a significant fraction contains less than 50% sentences of acceptable quality. In addition, many are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-proficient speakers, and supplement the human audit with automatic analyses. Finally, we recommend techniques to evaluate and improve multilingual corpora and discuss potential risks that come with low-quality data releases. |
|
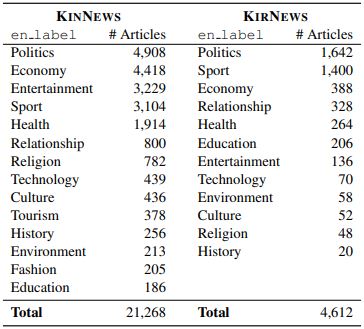
Recent progress in text classification has been focused on high-resource languages such as English and Chinese. For low-resource languages, amongst them most African languages, the lack of well-annotated data and effective preprocessing, is hindering the progress and the transfer of successful methods. In this paper, we introduce two news datasets (KINNEWS and IRNEWS) for multi-class classification of news articles in Kinyarwanda and Kirundi, two low-resource African languages. The two languages are mutually intelligible, but while Kinyarwanda has been studied in Natural Language Processing (NLP) to some extent, this work constitutes the first study on Kirundi. Along with the datasets, we provide statistics, guidelines for preprocessing, and monolingual and cross-lingual baseline models. Our experiments show that training embeddings on the relatively higher-resourced Kinyarwanda yields successful cross-lingual transfer to Kirundi. In addition, the design of the created datasets allows for a wider use in NLP beyond text classification in future studies, such as representation learning, cross-lingual learning with more distant languages, or as base for new annotations for tasks such as parsing, POS tagging, and NER. |
|
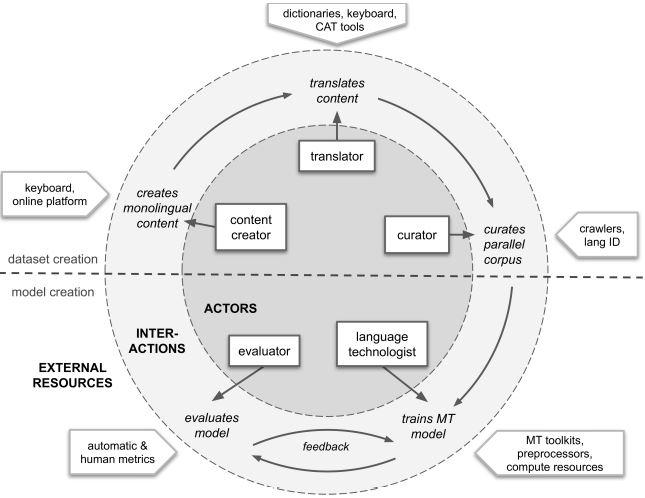
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has not yet been adequately solved. ‘Low-resourced’-ness is a complex problem going beyond data availability and reflects systemic problems in society. In this paper, we focus on the task of Machine Translation (MT), that plays a crucial role for information accessibility and communication worldwide. Despite immense improvements in MT over the past decade, MT is centered around a few high-resourced languages. As MT researchers cannot solve the problem of low-resourcedness alone, we propose participatory research as a means to involve all necessary agents required in the MT development process. We demonstrate the feasibility and scalability of participatory research with a case study on MT for African languages. Its implementation leads to a collection of novel translation datasets, MT benchmarks for over 30 languages, with human evaluations for a third of them, and enables participants without formal training to make a unique scientific contribution. |
|
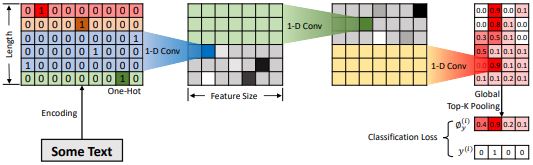
Text classification is a fundamental task in Natural Language Processing (NLP). In this paper, we propose a Weakly-Supervised Character-level Convolutional Network (WSCCN) for text classification. Compared to the word-based model, WSCCN extracting information from raw signals. Further, through the combination of global pooling and fully convolutional networks, our model retains semantic position information from stem to stern. Extensive experiments on the most widely-used seven large-scale datasets show that WSCCN could not only achieve state-of-the-art or competitive classification results but show critical parts of the text for classification. |
|
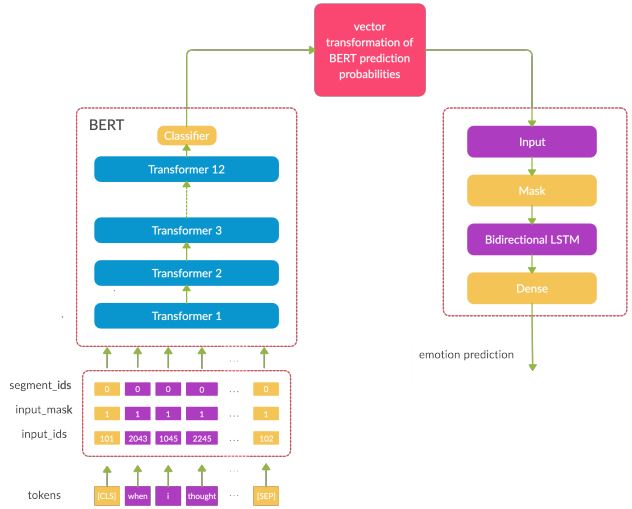
The popularity of using pre-trained models results from the training ease and superior accuracy achieved in relatively shorter periods. The paper analyses the efficacy of utilizing transformer encoders on the ISEAR dataset for detecting emotions (i.e., anger, disgust, sadness, fear, joy, shame, and guilt). This work proposes a two-stage architecture. The first stage has the Bidirectional Encoder Representations from Transformers (BERT) model, which outputs into the second stage consisting of a Bi-LSTM classifier for predicting their emotion classes accordingly. The results, outperforming that of the state-of-the-art, with a higher weighted average F1 score of 0.73, become the new state-of-the-art in detecting emotions on the ISEAR dataset. |
|
I have been a teaching assistant (TA)/tutor for the following courses/tutorial/workshops at University of Electronic Science and Technology of China (UESTC). |
|
|
|
I am fortunate that I have served in the following leadership positions while at UESTC.
|
|
|